



|
|
|
|
|
|
|
Rekurze je technika, při které funkce opakovaně volá samu sebe (přímá rekurze) - případně se mohou dvě funkce volat navzájem (nepřímá rekurze). Přitom je nutné, aby tato opakovaná volání měla konečný počet - v tom případě se jedná o konečnou rekurzi.
Správně definovaná konečná rekurze vyhovuje těmto dvěma požadavkům:
Pokud by rekurzivní volání nenarazilo na základní případ, šlo by o nekonečnou rekurzi s neúměrným nárokem na paměť počítače.Tato situace je ošetřena tak, že se Python zastaví po dosažení nastavené hloubky rekurze (implicitně ~ 1000 až 3000 cyklů - v závislosti na typu paměti RAM počítače) a vrací chybu při běhu programu.
Příbuznou procedurou jako rekurze je iterace (viz Kap. 3.1), která je méně náročná na paměť a je rychlejší než rekurze.
Iterativní funkci
def countdown (n):while n > 0: # omezující podmínka # pokračování tisku na témže řádku n = n-1# změna stavu počítadla # >>> countdown(4) --> 4 3 2 1
můžeme s pomocí rekurze přepsat takto:
def cntdwn (n):if n > 0: # zákl. případ # pokračování tisku na témže řádku cntdwn(n-1)# koncová (tail) rekurze # >>> cntdwn(4) --> 4 3 2 1
Průběh výpočtu funkce
| ni | ni - 1 | ni > 0 | print(ni) | Poznámka |
|---|---|---|---|---|
| 4 | 3 | T | 4 | |
| 3 | 2 | T | 3 | |
| 2 | 1 | T | 2 | |
| 1 | 0 | F | 1 | cntdwn (4) --> 4 3 2 1 |
Stojí za pozornost, že varianta funkce
def codo (n):if n > 0: # základní případ codo(n-1)# čelní (head) rekurze # >>>codo(4) --> 1 2 3 4
A ještě jinak se stejnými řádky:
def ctdn (n):if n > 0: ctdn(n - 1)# koncová (tail) rekurze # >>> ctdn(4) --> 4 3 2 1 0
Časté je použití příkazu
def cntd (n):if n == 0: # základní případ return # konec rekurze else : cntd(n - 1)# cntd(4) --> 4 3 2 1 0
Není snadné se v tom vyznat. Ve čtyřech uvedených příkladech velmi podobné rekurzivní funkce jsme viděli dva různé výstupy. Proč tomu tak je, souvisí se zákulisní aktivitou interpreta a paměti typu
V matematice známý pojem faktoriál čísla n (n!) je označení pro součin souvislé číselné řady 1 až n: n! = n * (n-1) * (n-2) * ... *1
Ukážeme si jeho různé vyjádření:
Matematická definice faktoriálu:
0! = 1# faktoriál nuly = 1 n! = n(n-1) Například: 25! = 15511210043330985984000000
Vyjádření pomocí iterace while...
def fact_w (n): f, i = 1, 0# hromadné přiřazení while i < n : i += 1; f = f*i# rozšířené přiřazení return f
Vyjádření pomocí iterace for...
def fact_f (n): f = 1for i in range(1, n+1): f = f*ireturn f
Vyjádření pomocí rekurze
def fact_r (n):if n < 2: # základní případ return 1return n * fact_r(n-1)# rekurzivní volání funkce
Dtto jinak:
def fact_rec (n):return 1if n == 1else n * fact_rec(n - 1)
Fibonacciho sekvence je řada čísel 0 ÷ n, v níž každé číslo je součet dvou čísel předcházejících:
F0, F1 = 0, 1; Fn = Fn-1 + Fn-2 pro n > 1
Iterativní výpočet může mít tento tvar:
def fibo_seq (n): n1, n2 = 0, 1 next_num = n2 count = 1while count <= n:
>>> fibo_seq(10) 1 2 3 5 8 13 21 34 55 89
Fibonacciho číslo je poslední hodnota Fibonacciho sekvence.
Opakovaný výpočet pomocí rekurze bývá pomalejší než výpočet pomocí iterace, protože zabírá více místa v paměti.
Koncová rekurze je v Pythonu považována za špatnou techniku, protože používá více systémových zdrojů než ekvivalentní iterativní řešení. Volání
def fibo_rec (n):# koncová rekurze if n == 0 or n == 1: return 1else :return fibo_rec(n-1) + fibo_rec(n-2)
>>>fibo_rec(10) 89
Mnohem rychlejší než rekurzivní verze je verze iterační, která by mohla vypadat takto:
def fibo_iter (n):# iterační řešení old, new = 0, 1if n == 0: return 0for i in range(n-1): old, new = new, old + newreturn old + new
>>> fibo_iter(10) 89
Vyzkoušejte volání
V dalším odstavci si ukážeme memoizovanou alternativu funkce
Když jsme si v předchozím odstavci pohrávali s výpočtem
Abychom pochopili proč, pohleďme na toto schéma volání funkce
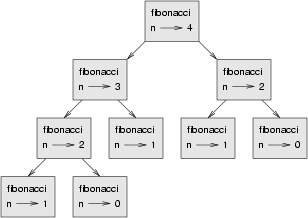
Schéma zobrazuje sadu funkcí v rámečcích se šipkami, ukazujícími na volané funkce. Nejvýše umístěná fce,
Spočítejme, kolikrát je voláno například
Dobrým řešením, zvaným memoizace (memoization), je ukládat si záznamy o spočítaných hodnotách do slovníku pro potřebu dalšího použití.
Takovýmto záznamům říkejme třeba
def fibo_mem (n): memo = {0:0, 1:1}# slovník (dictionary) if n not in memo: memo[n] = fibo_mem(n-1) + fibo_mem(n-2)return memo[n]
Slovník
Kdykoli je funkce
S použitím této verze náš počítač spočítá
>>> fibo_mem(30) 832040
Výrazné zlepšení výpočtu Fibonacciho čísla pomocí memoizace představuje výpočet s podporou
def memoize (fun):# dekorátorová funkce memo = {}def wrapper (x):if x not in memo: memo[x] = fun(x)return memo[x]return wrapper@memoize # dekorace funkcí def fibomem (n):if n == 0: return 0elif n == 1: return 1else :return fibomem(n-1) + fibomem(n-2)# >>> fibomem(100) ==> 354224848179261915075
class Memoize :# dekorátorová třída def __init__ (self, fn): self.fn = fn self.memo = {}def __call__ (self, *args):if args not in self.memo: self.memo[args] = self.fn(*args)return self.memo[args]@Memoize # dekorace třídou def fibomem (n):if n == 0: return 0elif n == 1: return 1else :return fibomem(n-1) + fibomem(n-2)# >>> fibomem(100) ==> 354224848179261915075
Všechny tři způsoby používají slovník
K vytvoření součtu všech čísel v seznamu s vnořeným seznamem potřebujeme traverzovat seznamem, navštívit každou položku uvnitř vnořené struktury a připočítávat číselné hodnoty k našemu součtu.
Potřebný program pro vytvoření součtu čísel v seznamu s vnořeným seznamem je díky rekurzi překvapivě krátký:
def recursive_sum (nested_num_list):# (vnořený seznam) sum = 0# počítadlo for element in nested_num_list: if type(element) == type([]): # je-li položkou seznam sum = sum + recursive_sum(element)else : sum = sum + elementreturn sum# --> 39 pro n_n_l = [2, 9, [1, 13], 8, 6]
Tělo fce se skládá hlavně ze smyčky
Funkce je napsána pouze pro hodnoty typu
Poněkud komplikovanější úlohou je nalezení největší hodnoty v seznamu s vnořeným seznamem. Následující definice funkce obsahuje
def recursive_max (nested_num_list):""" >>> recursive_max([2, 9, [1, 13], 8, 6]) 13 >>> recursive_max([2, [[100, 7], 90], [1, 13], 8, 6]) 100 >>> recursive_max([2, [[13, 7], 90], [1, 100], 8, 6]) 100 >>> recursive_max([[[13, 7], 90], 2, [1, 100], 8, 6]) 100""" largest = nested_num_list[0]# začínáme 1. elementem seznamu while type (largest) ==type ([]): largest = largest[0]for elementin nested_num_list:if type(element) ==type ([]):max_of_elem = recursive_max(element)if largest < max_of_elem: largest = max_of_elemelse :# element is not a list if largest < element: largest = elementreturn largest if __name__ == '__main__': import doctest doctest.testmod()
Jak je u doctestů [ne]dobrým zvykem, reakcí na správný výsledek při průběhu kódu je němé mlčení jako v našem případě. O tom, že náš prográmek chodí správně se přesvědčíme, když se zeptáme přímo:
>>> n_n_l = [2, [[100, 7], 90], [1, 13], 8, 6] >>> recursive_max(n_n_l) 100# správně viz doctest
Čertovým kopýtkem našeho problému je určení numerické hodnoty pro inicializaci proměnné
Práce s maticemi vyžaduje specifické znalosti maticového počtu. Na rozdíl od algebry v něm například obecně neplatí komutativní zákon pro součin, jenž však platí pro součet (rozdíl) c = a + b = b + a kde
Z toho vyplývá, že obě matice musí mít stejný rozměr
Násobení matice a o velikosti
Pokud je tato podmínka splněna, lze prvek
a b c
| 1 2 3 | | 7 8 | 1*7+2*9+3*3 | 1*8+2*2+3*1 | 34 15 |
| 4 5 6 | * | 9 2 | = ------------|------------ =
| 3 1 | 4*7+5*9+6*3 | 4*8+5*2+6*1 | 91 48 |
Rozměr výsledné matice c = a * b je tedy dán počtem řádků
a = [[1, 2, 3], [4, 5, 6]]# 2 řádky, 3 sloupce: a(2,3) b = [[7, 8], [9, 2], [3,1]]# 3 řádky, 2 sloupce: b(3,2) c = [[34, 15], [91], [48]]# 2 řádky, 2 sloupce: c(2,2) # c(1,1)= 1*7 + 2*9 + 3*3 = 34 # c(2,2)= 4*8 + 5*2 + 6*1 = 48
K vyjádření matic se často používají vnořené seznamy. Například, matice o rozměru 3x3 (3 řádky x 3 sloupce):

může být vyjádřena jako seznam s vnořenými seznamy stejné délky. Jednotlivé vnořené seznamy prezentují příslušné řádky matice:
>>>matrix = [[1, 2, 3], ... [4, 5, 6], ... [7, 8, 9]]# Tentýž zápis v úspornějším provedení: >>>matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
V maticovém počtu lze tyto vnořené seznamy označit jako řádkové matice, neboli vektory.
Řádek matice vybereme jako prvek vnějšího seznamu (indexy zde počínají nulou):
>>> matrix[1]# druhý řádek matice [4, 5, 6]
Položku určitého řádku označíme indexem řádku a indexem položky:
>>> matrix[1][1] 5
Výpočet součinu matic lze provést trojím použitím idiomu
matrix_mult1.py a = [[1,2,3], [4,5,6], [7,8,9]] b = [[7,8,9], [4,5,6], [1,2,3]]def matrix_mult1 (m1, m2):result = [[0 for row in range(len(m1))]# maketa výsledné for col in range(len(m2[0]))] matice for iin range(len(m1)):# rows in m1 for jin range(len(m2[0])):# cols in m2 for kin range(len(m2)):# rows in m2 result[i][j] += m1[i][k] * m2[k][j]return result
>>>%Run matrix_mult1.py >>> >>> matrix_mult1(a,b) [[18, 24, 30], [54, 69, 84], [90, 114, 138]]
Sevřenější tvar má toto řešení s komprehencí seznamu a s vestavěnými funkcemi
matrix_mult2.py def matrix_mult2 (m1, m2):return [[sum(x * y for x, y in zip(m1_r, m2_c)) for m2_c in zip(*m2)] for m1_r in m1]
>>>%Run matrix_mult2.py >>> >>> matrix_mult2(a,b) [[18, 24, 30], [54, 69, 84], [90, 114, 138]]
Pro úplnost si ještě uvedeme příklad funkce pro součet matic:
def matrix_add (m1, m2):result = [[0, 0], [0, 0]]
Práci s maticemi ulehčuje modul
Matice jako

Vyjádření řídké matice prostřednictvím seznamu obsahuje množství nul:
matrix = [ [0,0,0,1,0],
[0,0,0,0,0],
[0,2,0,0,0],
[0,0,0,0,0],
[0,0,0,3,0] ]
Poloha prvku v matici se vyjádří enticí (poř_číslo_řádku,
poř_číslo_sloupce). Číslování počíná nulou.
Alternativou je použití slovníku. Jako klíče můžeme použít entice, obsahující pořadová čísla řádků a sloupců. Zde je slovníkové vyjádření téže matice:
>>>matrix = {(0,3): 1, (2,1): 2, (4,3): 3}
Nenulové prvky matice jsou přístupné pomocí operátoru [ ]:
>>> matrix[0,3]0,3 je souřadnice mista 1
Pokud však narazíme na nulový prvek matice, dostaneme chybu:
>>> matrix[1,3]KeyError: (1, 3)
Tento problém řeší metoda
>>> matrix.get ((0,3),0) 1 >>> matrix.get ((1,3),0) 0
Jak už bylo uvedeno v první kapitole, mohou se při kontrole zdrojového kódu kompilací vyskytnout chyby skladebné (syntaktické) a
při interpretaci objektového kódu za běhu programu (run-time) takzvané chyby výjimkové, neboli
Při výskytu těchto událostí dojde k zastavení výpočtu a případně k poskytnutí stručné informace o (možné) příčině události - viz výpis chybové sekvence, zvaný
>>>File "<stdin>", line 1 print(55/2)) ^ SyntaxError: unmatched ')' # neshodný počet závorek
Při výskytu takovéto chyby se zastaví běh kompilace a zobrazí se informace s označením místa na řádku, kde k chybě došlo (
Při výskytu předpokládané výjimky (např. dělení nulou) zastaví Python běh programu a pokusí se zobrazit informaci o vzniklé chybě:
>>>Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero
Traceback je výpis chybové sekvence, který ukazuje sled volání funkcí vedoucích k chybě, například:
# traceback.py def moje_funkce ():muj_list = [1, 2, 3]# invokace deklarované funkce
>>>Tento výpis čteme od konce, neboť jeho poslední řádek obvykle obsahuje popis chyby a její typ. Ve výše uvedených dvojicích řádků se nalézá umístění inkriminovaných částí kódu.%Run traceback.py Traceback (most recent call last): File " ", line 1, in File " ", line 3, in moje_funkce IndexError: list index out of range # index mimo rozsah >>>
Kromě standardních (built-in) výjimek je možné používat vlastní výjimky a to deklarací:
Klauzulí raise lze vyvolat výjimku kdykoliv to je potřebné:
>>>x = "Hello!" >>>if not type(x) is int: # sledovaná podmínka raiseTypeError(": Jen celá čísla!") # reakce programu Traceback (most recent call last): # chybové hlášení> File "<stdin>", line 2, in <module> TypeError: : Jen celá čísla!# sledovaná podmínka
Další příklad:
>>>x = -5 >>>if x < 0 : raiseException(": Pouze x > 0!") Traceback (most recent call last): File "<stdin>", line 2, in <module> Exception: : Pouze x > 0!
Ověření správnosti uživatelem zadaného výrazu lze také zajistit předsazeným příkazem
>>>x = -5 >>>assert x > 0# lze doplnit komentář Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError # název chyby je zde dosazen automaticky
Jiný příklad s komentářem:
>>>import sys >>>assert ('linux' in sys.platform),"Tento kód běží jen ve Windows!"Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: Tento kód běží jen ve Windows!
Použití příkazu
Příkaz
>>>spin =int (input ('Zadej kladné číslo: '))# viz Poznámka Zadej kladné číslo:# -7 >>>assert (spin > 0), 'Jen kladná čísla, prosím!'Traceback (most recent call last): File <stdin>, line 1, in <module> AssertionError: Jen kladná čísla, prosím!
Chceme-li zařídit aby provádění programu pokračovalo i po výskytu určité chyby, provedeme takzvané "ošetření výjimky" (exception handling).
To zpravidla spočívá v použití klauzule
try : uvádí ověřovaný blok kódu - provedou se všechny výrazy, pokud se nenarazí na výjimkuassert uvádí ověřovací podmínku, která rozdělí tok výpočtu do dvou větví - pokračování programu nebo chybové hlášeníexcept {-, NameError, TypeError, ...}: následný blok kódu ošetří chybu či nesplněnou podmínku z bloku 'try' nebo 'assert'else : uvádí blok kódu při splnění podmínky v bloku 'try'finally : následný kód se provede vždy, bez ohledu na 'výjimky'
Klauzulí
Klauzule
Rozšíření příkladu se zadávanou hodnotou
try_spin_int.py spin = int(input('Zadej kladné číslo: '))try :assert (spin > 0), print('Jen kladná čísla!')except :spin = int(input('Zadej kladné číslo: '))
Evokací skriptu v konzole Thonny získáme výstup:
>>>%Run try_spin_int.py Zadej kladné číslo:-5 # zkuste zadat "pět" Jen kladná čísla!: Zadej kladné číslo:5 Přijato : 5 >>>
Pěkný příklad řešení kořenů kvadratické rovnice
import math def KvadrRovnice (a, b, c):try :assert a != 0, "Chyba, nulový kvadratický člen" D = (b*b - 4*a*c)# hodnota diskriminantu assert D > 0, "Chyba, diskriminant je menší než 0" r1 = (-b + math.sqrt(D))/(2 * a)# první kořen rovnice r2 = (-b - math.sqrt(D))/(2 * a)# druhý kořen rovnice except AssertionError as msg:# vestavěná formule
Klauzule
>>> KvadrRovnice(-1, 5, -6) Kořeny rovnice jsou : 2.0 3.0 >>> KvadrRovnice(0, 5, -6) Chyba, nulový kvadratický člen >>> KvadrRovnice(1, 1, 6) Chyba, diskriminant je menší než 0
Kombinaci
# MyExcept.py class MyExcept (Exception ):def __init__ (self, length, atleast): Exception.__init__(self) self.length = length self.atleast = atleasttry: s = input("Zadej heslo: ")if len(s) < 7:raise MyExcept(len(s), 7)except MyExcept as x:else:
Jak vidno, naše třída dědí z vestavěné třídy
>>>%Run MyExcept.py Zadej heslo:Pepa # via klávesnice MyExceptError: Heslo je krátké (4<7) >>>%Run MyExcept.py Zadej heslo:František # via klávesnice Heslo je v pořádku >>>
Účelem kopírování je vytvoření nezávislé, autonomní kopie objektu. Tuto kopii lze provést jako mělkou (shallow) nebo důkladnou (deep).
Rozhodující vlastností kopírovaného objektu je jeho složení. Jednoprvkový objekt nebo jednoduché prvky kontejneru (list, tuple, set, dict) lze nezávisle reprodukovat jako
Za kopii nelze považovat přiřazení téhož objektu k více proměnným - viz alias.
Zdánlivou kopii neboli alias vytvoříme přiřazením téhož objektu k více jménům, což lze provést najednou v jednom řádku:
>>> a = b = [1, 2, 3] >>> id(a), id(b), id([1, 2, 3]) (59931496, 59931496, 59931400)
nebo postupně
>>> orig = [2, [True, False], "asi"]# prosté přiřazení >>> kopie = orig# kopie přiřazením (alias) >>> id(orig), id(kopie), id([2, [True, False], "asi"]) (59931464, 59931464, 59931688)
Schema vztahů může vypadat takto:

Proměnné se shodnými ID odkazují na stejný objekt. Změny objektu provedené prostřednictvím jednoho aliasu se projeví i u dalšího aliasu:
>>> b[0] = 5 >>> a [5, 2, 3]
Při mělké (shallow) kopii se v možném rozsahu vytvoří nový samostatný klon originálu. Mělkou kopii můžeme provést čtverým způsobem - například pro seznam:
>>>orig = [2, [True, False], "asi"]# seznam v seznamu
Použitím vestavěné metody
>>> orig_shall_1 = orig.copy()
Konverzí seznamu na entici (případně obráceně):
>>> orig_shall_2 = list(orig)
Použitím úsekového operátoru:
>>> orig_shall_3 = orig[:]
Použitím metody
>>>import copy >>> orig_shall_4 = copy.copy (orig)
Ve všech čtyřech uvedených případech se nezávisle kopírují pouze jednoduché členy kopírovaného seznamu. Prvky vloženého seznamu jsou závisle propojeny se svým originálem:
>>> orig[2] = "yes"; orig[1][1] = 8 >>> orig_shall_three; orig [2, [True, 8], 'asi']# orig_shall_three [2, [True, 8], 'yes']# orig
Při důkladné (
Důkladnou kopii vytvoříme importovanou metodou
>>> from copy import deepcopy >>> orig_deep = deepcopy(orig) >>> orig[2] = "snad"; orig[1][1] = True >>> orig_deep; orig [2, [True, False], 'asi']# orig_deep [2, [True, True], 'snad']# orig
Text, zaměřený specielně na kopírování entic, viz kap. 9.2.
Modul pydoc použijeme k prohledávání knihoven Pythonu, instalovaných na počítači. Na příkazový řádek konzoly napíšeme:
C:\> python -m pydoc -b Server ready at http://localhost:52142/ Server commands: [b]rowser, [q]uitserver>
Příkaz spustí libovolný nepoužitý port v počítači a otevře stránku ve webovém prohlížeči. Seanci serveru ukončíme příkazem
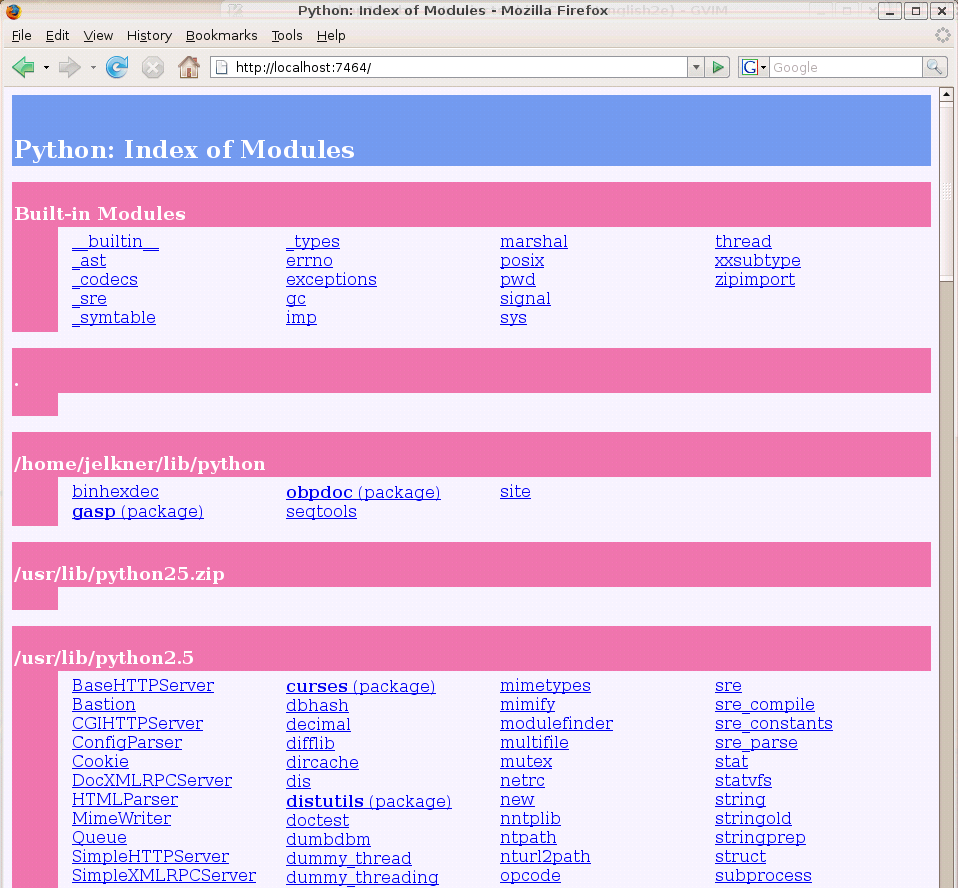
Je to výčet všech knihoven Pythonu na vašem počítači. Klikem na jméno modulu otevřeme novou stránku s dokumentací o vybraném modulu. Například, klik na slovu
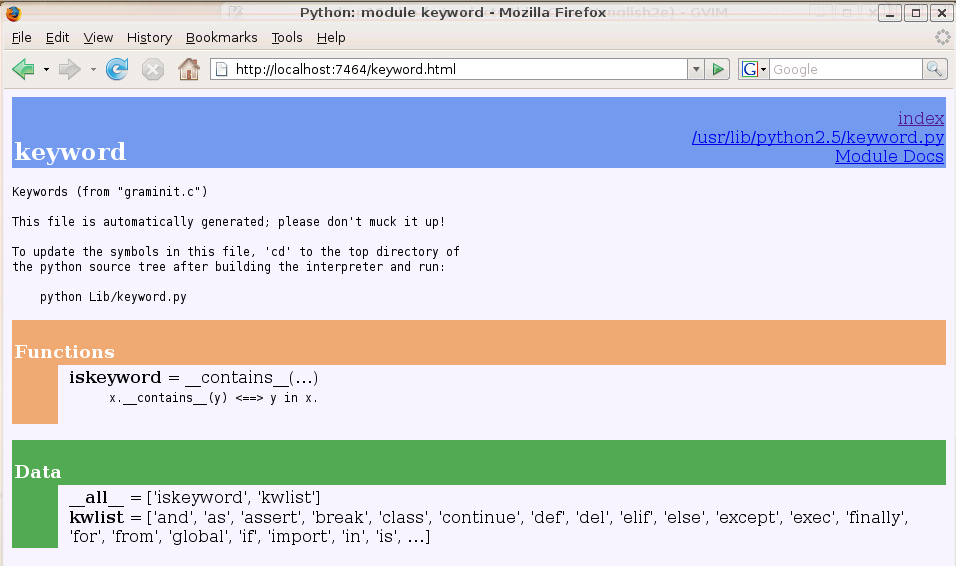
Dokumentace pro většinu modulů obsahuje až tři barevně označené sektory:
Modul
>>> from keyword import *
>>> iskeyword('for')
True
>>> iskeyword('all')
False
Datový prvek
>>> from keyword import * >>> print(kwlist) ['and', 'as', 'assert', 'async', 'await','break', 'class', 'continue','def', 'del', 'elif', 'else', 'except','finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield', 'False', 'None', 'True']
Doporučujeme časté používání služby
Funkce by měla vyhovět všem doctestům.def recursive_min (nested_num_list): """ >>> recursive_min([2, 9, [1, 13], 8, 6]) 1 >>> recursive_min([2, [[100, 1], 90], [10, 13], 8, 6]) 1 >>> recursive_min([2, [[13, -7], 90], [1, 100], 8, 6]) -7 >>> recursive_min([[[-13, 7], 90], 2, [1, 100], 8, 6]) -13 """
Funkce vyhoví všem doctestům?def recursive_count (target, nested_num_list): """ >>> recursive_count(2, [2, 9, [2, 1, 13, 2], 8, [2, 6]]) 4 >>> recursive_count(7, [[9, [7, 1, 13, 2], 8], [7, 6]]) 2 >>> recursive_count(15, [[9, [7, 1, 13, 2], 8], [2, 6]]) 0 >>> recursive_count(5, [[5, [5, [1, 5], 5], 5], [5, 6]]) 6 """
def flatten (nested_num_list): """ >>> flatten([2, 9, [2, 1, 13, 2], 8, [2, 6]]) [2, 9, 2, 1, 13, 2, 8, 2, 6] >>> flatten([[9, [7, 1, 13, 2], 8], [7, 6]]) [9, 7, 1, 13, 2, 8, 7, 6] >>> flatten([[9, [7, 1, 13, 2], 8], [2, 6]]) [9, 7, 1, 13, 2, 8, 2, 6] >>> flatten([[5, [5, [1, 5], 5], 5], [5, 6]]) [5, 5, 1, 5, 5, 5, 5, 6] """
|
|
|
|
|
|
|