


|
|
|
|
|
|
|
Cílem této knihy je naučit čtenáře myslet jako erudovaný programátor. Tento způsob myšlení spojuje některé z výtečných rysů matematiky, jakož i technických a přírodních věd. Programátoři stejně jako matematici používají formálního jazyka k vyjádření svých myšlenek. Stejně jako inženýři i oni navrhují objekty sestavováním částí do celků a porovnávají výsledky jednotlivých alternativ. Stejně jako vědci i programátoři pozorují chování komplexních systémů, tvoří hypotézy a předpoklady výsledků.
Nejdůležitější dovedností programátora je schopnost řešit problém. Řešit problém vyžaduje schopnost jej formulovat, tvořivě přemýšlet o možnostech řešení a zvolené řešení potom jasně a stručně vyjádřit. Učit se programovat je vynikající příležitost pro osvojení těchto dovedností.
Budeme se tedy jednak učit programovat, což je užitečná dovednost sama o sobě, jednak budeme programování používat jako prostředek k dosažení jistého cíle. Jak budeme v učení postupovat , bude se nám tento cíl stávat zřejmější.
Přirozené jazyky jsou jazyky, kterými lidé hovoří - čeština, angličtina, španělština, atd. Každý tento jazyk lze popsat jeho slovní zásobou a gramatikou .
Formální jazyky jsou jazyky, sestavené záměrně pro nějaký účel. Matematika například používá svůj formální jazyk k vyjádření vztahů mezi čísly a symboly. Chemici používají svůj formální jazyk k zobrazení chemických struktur a procesů.
Programovací jazyk je rovněž formálním jazykem, používaným pro řízení činnosti počítače. Podobně jako přirozené jazyky se programovací jazyk řídí pravidly pro skladbu (syntax) a pro význam používaných slov - sémantiku (semantics).
Pravidla skladby programovacího jazyka jsou dvojího druhu:
I když formální a přirozené jazyky mají mnho společných rysů - slovní zásobu (tokeny), strukturu, syntaxi a sémantiku - mají také mnoho rozdílů:
Protože přirozený jazyk používáme od nejútlejšího dětství, můžeme mít problémy s používáním formálního jazyka. Někdy lze rozdíl mezi formálním a přirozeným jazykem přirovnat v menší míře k rozdílu mezi prózou a poezií.
Zde je několik rad pro čtení programů (a jiných formálních jazyků). Za prvé, mějme na paměti, že text formálního jazyka je významově zhuštěnější než text přirozeného jazyka a proto jeho čtení zabere více času. Také jeho struktura je velice důležitá, takže nebývá dobrým nápadem číst pouze zhora dolů, zleva doprava. Místo toho si zvykejme provádět v mysli rozbor skladby (parsing), rozeznávaje znaky a hodnotíce strukturu. Nakonec nezapomínejme, že záleží na maličkostech. Nepřesnost, která nám projde v přirozeném jazyce, má ve formálním jazyce dalekosáhlý význam.
Program je posloupnost instrukcí, které určují, jak má být výpočet proveden. Výpočtem může být řešení matematické úlohy, jako je např. řešení systému rovnic či určení kořenů polynomu nebo jím může být symbolický výpočet, jako je vyhledání a výměna textu v dokumentu.
Podrobnosti se v různých jazycích liší, ale některé základní instrukce se vyskytují téměř v každém jazyce:
Věřte či nevěřte, to je téměř všechno z programování. Každý program, který kdy použijete, jakkoliv komplikovaný, se bude skládat z instrukcí více či méně podobných výše uvedeným. Programování můžeme také prezentovat jako proces rozdělování komplexní úlohy do menších a menších podúloh, až tyto podúlohy jsou tak jednoduché, že se dají provést pomocí těchto zákládních instrukcí.
Programovací systém je spojení programovacího jazyka, příslušných knihoven a
programového vybavení (kompilátor, interpret, virtuální stroj) pro práci s
tímto jazykem. Programovací jazyk Python je jazyk vyšší úrovně
, stejně jako například C++,
PHP a Java.
Interpret jazyka je psán v jazyce C pro CPython, v jazyce Java
pro Jython, v jazyce Python pro PyPy. IronPython je úzce spojen se systémem .NET Framework
.
Jazykem nejnižší úrovně je
Program v jazyce vyšší úrovně se nazývá
Pokud jsou tyto soubory přímo určeny ke zpracování interpretem
Pythonu, říkáme jim
Důležitou součástí programového vybavení Pythonu je interní sada programů,
označovaná jako
Na obrázku vidíme zjednodušené schematické propojení jednotlivých částí
realizačního procesu při zpracování zdrojového kódu.
Instrukce zdrojového kódu jsou najednou kompilovány
(přeloženy a kontrolovány z hlediska skladby) a přetvořeny na mezilehlý
Interpret postupně čte objektový kód a v součinnosti virtuálního
stroje s příslušnými knihovnami (Library modules) jej v časové fázi zvané
Popsaný proces převodu zdrojového kódu na strojový platí i pro kód,
zapisovaný přímo do příkazového řádku interaktivní konzoly (
Příkaz je interně kompilován, vytvořený bytecode (
Programování je složitý proces a protože jej provádí lidská bytost, je často
provázeno chybami.
Chyba v programu je z potměšilých důvodů označována jako
V programu se mohou vyskytnout tři druhy chyb: chyby související se skladbou
programu (
Python může provést výpočet jenom pro takový program, který má správnou skladbu
(syntaxi). Slovo
Pro většinu čtenářů nepředstavuje několik málo chyb ve skladbě textu výraznou
překážku pro jeho správné pochopení. Python tak snášenlivý není.
Před každým prováděním skriptu (runtime) se provádí jeho formální kontrola
kompilátorem. Jakmile se ve zdrojovém kódu objeví syntaktická chyba, interpret
vytiskne
Druhým typem chyb je chyba, která se vyskytne až při
Takto ošetřené chyby se také nazývají
Pro úplnost je nutné zde uvést také chyby, které zastaví běh programu bez naznačení příčiny, případně chyby, které způsobí nekončící běh programu na pozadí.
Třetím typem chyb jsou
Problém spočívá v tom, že program, který jsme napsali, není ten program, který jsme chtěli napsat. Vyznění programu (jeho sémantika) je špatné. Nalezení sémantických chyb může být někdy náročné, protože to vyžaduje zpětné porovnávání výstupu s tím, co jej v programu způsobuje.
Vyhledávání chyb je nejdůležitější dovednost, kterou potřebujeme získat. I když to může být frustrující, vyhledávání chyb je intelektuálně nejbohatší, nejnáročnější a nejzajímavější část programování.
Svým způsobem připomíná hledání chyb práci detektiva. Jsme konfrontováni s indiciemi, z nichž máme určit procesy a události, které vedly k výsledkům, jež máme před sebou.
Vyhledávání chyb je něco jako experimentální věda. Jakmile nás napadne, v čem může chyba spočívat, upravíme program a vyzkoušíme jej. Byla-li naše hypotéza správná, můžeme získanou zkušenost zobecnit a použít příště. Nebyla-li naše hypotéza správná, musíme si vymyslet jinou.
Pro někoho splývá vyhledávání chyb s programováním. To jest programování jako postupné odstraňování chyb z programu, až posléze program dělá to, co si přejeme. Jinými slovy, začneme s programem, který "něco " dělá a postupně jej malými úpravami a laděním přeměníme na fungující program, který dělá to, co si přejeme.
Při práci s programovacím jazykem Python můžeme používat některou z řady systémových konzol - CMD, (Windows Command Processor), Terminál - plus konzoly aplikací IDLE a Thonny.
Pro nastavení konzoly do požadované složky (např. F:/Howtopy) používáme postup, který lze použít u všech výše uvedených konzol, kromě IDLE a Thonny:
C:/> cd /d F:/Howtopy# změna složky F:\Howtopy>
U konzoly Terminál lze variantně vyhledat v
Instalace pythonu je jednoduchá a ještě jednodušší. Ta jednoduchá spočívá v tom, že si na domovské stránce
Pythonu
vyberete vhodný instalátor poslední verze (např. python-3.14), stáhnete do počítače, kde jej spustíte s tím, že si pohlídáte, zda bude instalace umístěna do systémového místa, např.
\Python314
Stručnou ilustraci právě popsaného lze nalézt na stránce Instalace Pythonu pro
Windows
Instalace není drobek, zabere na disku 560 MB ale obsahuje mnoho dober:
Interpret Pythonu se uplatňuje v interaktivním režimu otevřené konzoly a v programovém režimu (při realizaci kódu, zapsaného do souboru).
V interaktivním režimu píšeme text kódu přímo na příkazový řádek
interaktivní konzoly - říkejme jí také
Interaktivní konzolu otevřeme v systémové konzole přikazem
Interaktivní konzola se také označuje akronymem
Činnost interaktivní konzoly ukončíme příkazy
C:\> python# invokace REPL v systémové konzole Python 3.14.0 (tags/v3.14.0:ebf955d, Oct 7 2025, ...) >>> 2+3# příkazový řádek v REPL 5# výstup >>>quit ()# vracíme se zpět do konzoly
Skupina znaků
Práce v interaktivní konzole (shellu) je vhodná pro testování krátkých kódů.
Interpret zadaný text
přečte, vyhodnotí, postupně přeloží, předá počítači a vrátí (vytiskne) výsledek.
Interaktivní prostředí interpreta lze použít jako jednoduchý kalkulátor s operátory
Přístup k prostředí Pythonu pro jeden úkon lze zajistit z příkazového
řádku
# Přepínač -czpůsobí výstup v konzole: C:\> python -c "print('Ať žije Slávie!')" Ať žije Slávie!# Případně: C:\> py -c "print(2+5)" 7# Zábavné je toto zadání: C:\> python -c "import this"
V programovém režimu zapíšeme kód (program) nejprve do souboru. S použitím textového editoru v
# trampolina.py # ignorované záhlaví # text skriptu (kód)
Dle zavedené konvence dáváme souborům s programem v Pythonu příponu
Program potom můžeme aktivovat tak, že na příkazový řádek systémové konzoly (například
Terminál) zapíšeme název souboru za slovem
F:\howto-py\ch-01> pythontrampolina.py 5# proveditelný příkaz zadaného souboru se ihned realizuje
Tento skript lze realizovat interpretem Pythonu při splnění dvou předpokladů:
V interaktivní konzole Pythonu můžeme zůstat, použijeme-li při invokaci přepínač
F:\howto-py\ch-01> python -itrampolina.py 5# provedný příkaz >>># zůstáváme v konzole Pythonu
Při zpracování skriptu
Pokud tento soubor
F:\howto-py\ch-01> python Python 3.14.0 (tags/v3.14.0:ebf955d, Oct 7 2025, ...) >>>import trampolina 5# provedený příkaz z importu >>> quit# návrat do prostředí Terminálu
K vytvoření složky
F:\howto-py\ch-01> python -mtrampolina 5
Python vytváří kompilaci zdrojového kódu vždy ale kompilovaný soubor ukládá
do externí složky
Aplikace IDLE je program pro psaní kódu v Pythonu a pro jeho zpracování interpretem. Při jeho spuštění se implicitně objeví interaktivní okno interpreta (
Na obrázku vidíme ukázku použitých oken Shell a Editor:
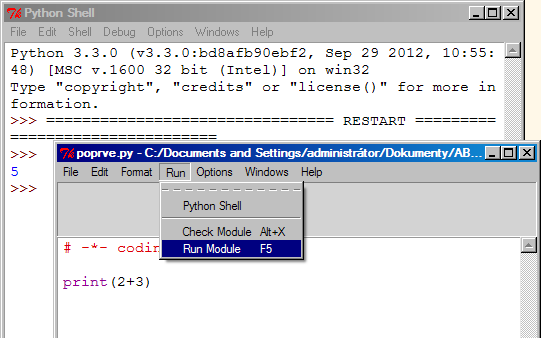
V okně editoru je zapsán příkaz k tisku, v okně interpreta je výstup z realizovanho kódu.
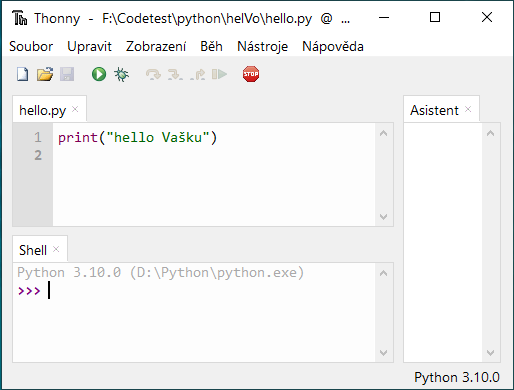
Aplikace Thonny je příjemné IDE Pythonu pro nerozsáhlé práce. Toto prostředí poskytuje řadu užitečných pomocných oken (Asistent, Shell, Výjimky, Soubory, Nápověda, Poznámky, Inspektor objektů, Osnova, ... ). Má také, jak vidno, české prostředí. Na rozdíl od IDLE poskytuje Thonny obě pracovní okna najednou.
Aplikaci Thonny otevřeme ikonou v hlavním panelu (liště) obrazovky.
Instalační soubor, například
Instalací přes
C:\> pip3.exeinstall thonny
Takto si ovšem do systémového uložiště
(například
Výraz (expression) je kombinace hodnot, proměnných, operátorů a
případně i volání funkcí. Zapíšeme-li výraz na příkazový
řádek shellu, interpret jej
>>> 1 + 1# výraz 2 >>>len ("hello")# výraz 5
V ukázce vidíme vestavěnou funkci
Příkaz (statement) je instrukce, kterou může interpret provést.
Samotný příkaz však neprodukuje žádný výstup. Dosud jsme poznali pouze příkaz
přířazení
Blok je část programového textu, provedená jako ucelená jednotka. Blokem je soubor, tělo funkce, definice třídy; blokem je i každý příkaz a výraz , zadaný v interaktivní konzole interpreta Pythonu.
>>>x = 27; x# příkaz k přiřazení hodnoty ke jménu proměnné 27 >>>y = 3+5; y# příkaz k přiřazení výrazu (3+5) ke jménu proměnné 8
Vyhodnocení výrazu generuje hodnotu a proto se výrazy mohou vyskytovat jen na pravé straně příkazu přiřazení.
Text programového kódu čte interpret z řádku interaktivní konzoly nebo z řádku souboru. Kód se zapisuje a ukládá do paměti po blocích, přednostně co řádek, to blok. Bloky mohou být i do sebe vnořené.
>>>def SayHello (name):# záhlaví funkce # tělo funkce >>>x = 2 + 5# nový blok
Pokud se blok nevejde na jeden fyzický řádek, lze jej rozdělit na menší části, které se na jeden fyzické řádky vejdou a které dohromady tvoří jeden logický řádek.
Rozdělení textu se provádí vloženým zpětným lomítkem (\) nebo se k rozdělení
použijí existující závorky (), [], {}, jejichž koncové závorky se umístí na
následující řádek.
Takto lze rozdělit i závorky kolem argumentu funkce:
>>># --> Rozdělení logického řádku >>># --> 7
Blok kódu začíná počátkem řádku nebo odsazeným řádkem textu. Všechny řádky stejného bloku mají stejné odsazení. Deklarace bloku končí změnou odsazení. Doporučovaná velikost odsazení jsou 4 mezery.
Deklarace více bloků na jednom řádku lze v interaktivním prostředí oddělit středníkem:
>>>a,b = 10,30; a,b# hromadné přiřazení a invokace proměnných a,b (10, 30)
Pro vkládání údajů do programu z klávesnice se používá funkce
>>>n =input ("Zadej součet: "); n# následuje klik uživatele Zadej součet:4+3**2 # reakce uživatele '4 + 3**2'# zadaný vstup je následně vytištěn jako string >>># s poměnnou n lze dále pracovat
Chceme-li jako vstup zadat výraz, který se i vyhodnotí, použijeme funkci
>>>eval ("6+7")# argumentem má být řetězec 13 >>>eval (input ("Zadej součet: ")) Zadej součet:4+3**2 # vložený výraz 13# zadaný vstup je vyhodnocen a vytištěn >>>eval (input ('Zadej výraz Pythonu:')) Zadej výraz Pythonu:2.5 + 3**4 # vložený výraz 83.5# zadaný vstup je vyhodnocen a vytištěn
Protože je zavedenou konvencí začínat programování pozdravem "Hello World!",
uvedeme si jeho ukázku také. V tomto případě se jak zápis kódu, tak jeho
vyhodnocení a výstup uskuteční v konzole Pythonu. Použijeme k tomu funkci
V Pythonu 2.x bychom použili příkaz:
>>>
Uvozovky označují začátek a konec hodnoty typu řetězec (
V Pythonu 3.x je
>>>
Na funkci
>>>
Programy se častěji čtou než píší a jak se program stává větším a
složitějším, stává se také méně přehledným. Formální
jazyky jsou hutné a často je obtížné při pohledu na část kódu určit, co má být
prováděno a proč.
Proto je dobré doplnit program poznámkami, které vysvětlují, co příslušná část
programu má
provádět. Poznámky či komentáře uvádíme symbolem
>>>minute = 40# minuty vyjádřené procentem hodiny >>>percentage = (minute * 100)// 60; percentage 66
Všechno od znaku
Potřebujeme-li komentovat více řádků, umístíme znak
""" Tento text je komentářem, nikoliv zdrojovým kódem. """
Jediné dva stavy, které umí počítač ve svém elektronickém obvodu rozlišit,
je přítomnost či nepřítomnost elektrického náboje. Těmto stavům se přisuzuje
význam hodnoty
Při komunikaci s počítačem jsou všechný tisknutelné i netisknutelné (řídící)
znaky vyjádřeny kódovými čísly, neboli
Souvztažnost čísel se znaky je vyjádřena různými kódovanými sadami znaků.
Kódování
Zbývající paměťový prostor (128 čísel) jednoho bajtu je využíván různými
dalšími sadami znaků pro potřebu dalších jazyků, případně pro "rozšířenou"
verzí
Společným rysem těchto seznamů je to, že to jsou zároveň
S příchodem Internetu začala mnohost kódovacích sad nevyhovovat. Na počátku
90. let minulého století byl do používání uveden systém Unicode, jenž
definuje číselnou řadu
Samotná sada znaků Unicode však ještě není kódování. Je to pouhý seznam (codespace) čísel a jim odpovídajících znaků. Pro praktické používání znakové sady Unicode byly vyvinuty 3 způsoby kódování (kódovací schemata): UTF-8, UTF-16 a UTF-32. Každé toto kódování zahrnuje všechny znaky Unicode, liší se však počtem bajtů pro vyjádření jednoho znaku.
Python implicitně používá kódování
>>> 1 2
File "<stdin>", line 1
1 2
^
SyntaxError: invalid syntax
V mnoha případech Python ukáže místo, kde k chybě došlo, ale toto označení není
vždycky
správné. Také příčina chyby není vždy podrobně uvedena. Takže nám nezbývá, než
se řádně
naučit pravidla skladby. V našem příkladě si Python stěžuje, protože mezi čísly
není
žádný operátor.
Traceback (most recent call last): File "<stdin>", line 1, in ?Toto je chyba při běhu programu, podrobnějiNameError: name 'tvaroh' is not defined
>>> 'Toto je test'
. . .
Poté vytvořte skript s názvem uložte a spusťte jej znova. Co se stalo tentokrát?
|
|
|
|
|
|
|